


Outlook in AI & Nvidia's Strategy
Current developments in the space

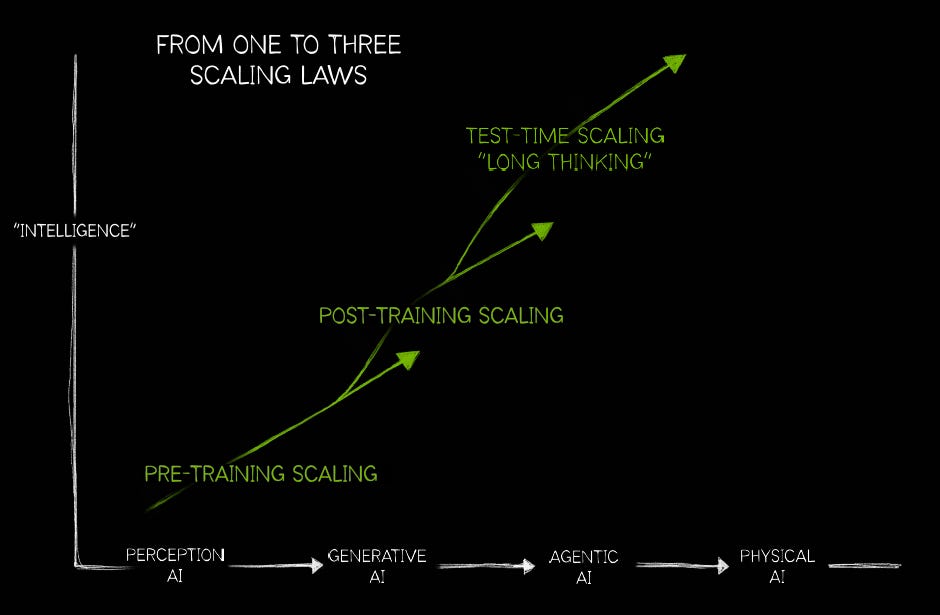
AI’s new scaling laws
The biggest recent development in AI is the emergence of inference-time scaling. The original scaling law was purely focused on the initial training phase of a model, and it basically meant that training larger models on more training data and for longer periods of time gives rise to more predictive models. The attraction with inference-time scaling is that it gives rise to two additional scaling laws, one in the post-training phase and one during inference. The basic idea behind inference-time scaling is simple, rather than giving a model one shot to come up with an answer, you give it time to reason, consider multiple options, verify which one is the most likely to finally produce the most thoughtful answer possible. This requires much more compute during the inference phase, but also during post-training.
The main idea on the latter is that you can now also start scaling compute to teach models on how to reason, which is done with reinforcement learning. Originally this was done by human feedback, i.e., a human assesses whether an answer or chain-of-thought step is accurate, but the beauty is that this can now be fully automated. The way this works is that you have an AI model which is a specialist at coding or maths, and this model can generate tons of example coding or maths problems while knowing how to solve them. So now it can teach this to the new foundation model you’re training. At each step where the foundation model is trying to solve the coding or maths puzzle, the specialist model can give a positive or negative reward to let the foundation model know whether it is on the right track or not. So if the proposed next step is correct, the model being trained gets a positive reward whereas if it makes an error, the reward is negative.
If you keep repeating this process for millions or billions of example problems, until the foundation model has learned how to solve them all properly, you’re going to have an expert coder or maths wiz at some stage. This process is called reinforcement learning and this is now the second scaling law. This is Jensen giving further background on AI’s three scaling laws during the latest earnings call:
“There are now multiple scaling laws. There's the pre-training scaling law, and that's going to continue to scale because we have multimodality and we have data that comes from reasoning that are now being used to do pre-training as well. The second is the post-training scaling law, using reinforcement learning from human feedback, reinforcement learning from AI feedback and reinforcement learning from verifiable rewards. The amount of computation you use for post-training is actually higher than pre-training. And while you're using reinforcement learning, you generate an enormous amount of synthetic data, so AI models are basically generating tokens to train AI models.
The third part is test-time compute or reasoning, i.e. long thinking, inference scaling. They're all basically the same ideas, you have a chain-of-thought, or you have deep search. The amount of tokens generated for inference compute is already 100x more than the one-shot capabilities of large language models, and that's just the beginning. The idea is that next generations could have thousands, millions times more compute than today with hopefully extremely thoughtful, simulation-based and search-based models.
The question is, how do you design such an architecture? Some of the models are autoregressive, some are diffusion-based, sometimes you want your data center to have disaggregated inference, sometimes it is compacted… And so it's hard to figure out what the best configuration of a data center is, which is the reason why NVIDIA's architecture is so popular. We run every model and we are great at training. But the vast majority of our compute today is actually inference and Blackwell takes all of that to a new level, we designed Blackwell with the idea of reasoning models in mind. For long thinking inference-time scaling, reasoning AI models are now tens of times faster and 25x higher throughput, so Blackwell is going to be incredible across the board.
Also, when you look at training, Blackwell is many times more performant. So, when you have a data center, that allows you to configure and use your data center for doing more pre-training or more post-training or scaling out your inference, our architecture is fungible and easy to use in all of those different ways. And so we're seeing in fact much more concentration of a unified architecture than ever before.”
To realize these two new scaling laws, synthetic data generation is key as it allows models to be post-trained with reinforcement learning for complex problem solving. This is a former researcher at OpenAI and DeepMind explaining how synthetic data can be incredibly powerful, this is via Tegus’ expert network:
“For ChatGPT, more than 50% of the data in GPT4 was synthetic. Most models now that are being trained and that haven't been released yet, all the big ones, almost 80% of the data is synthetic. That's the game now. People aren't talking about it because it can be a competitive edge, but everyone's using it. The quality of the synthetic data is really very good. There's a misunderstanding, people think that synthetic data is somehow worse than human data. This is a really big mistake, I can give you an example of a project I worked on where we only used synthetic data and it was the best in the world, beyond human capabilities. It was at Google DeepMind and we were going to build something called AlphaGo to play Go, and we wanted to train it by itself.
We looked at Deep Blue, which is the big chess computer IBM built and that had 9,000 programmers and lots of experts. We didn't want to go down that route, we had a team of about six. What we did is, we got two machines and we were going to teach them how to play Go. We worked out how long that would take and actually, that'll take a long time. So why don't we do a test run with a simple game? If it works for the simple game, then we'll do it for Go. That's what we did. The simple game we chose was chess. We just gave it the rules of chess, two machines and they play each other. In each game, that's generating synthetic data and we left it alone for a month. After a month, we switched it on and on the team, we had four grandmasters. It beat every one of them just out of the gate on day zero. In that one month, those two computers had played more games of chess than all of humanity combined in its entire history.
People think that synthetic data is rubbish, but if you give it the rules and you tell it what winning is, it can be materially better than humans. We can create really superhuman products with synthetic data.”
This is the reason why Meta and Broadcom are talking about building one million or more GPU clusters, scaling laws are still strong in the training phase. Even if they’re wrong on this, these types of datacenters can still be deployed to enable the strong scaling law in inference-time.
While DeepSeek introduced a number of compelling algorithmic improvements to train and infer AI models, the key long term drivers of GPU demand are the number of applications that will be using AI—ranging from automated software to robotics and robotaxis—the demand for these apps, and the compute intensity to train and infer those apps. While it’s a difficult exercise to estimate future computational needs, Jensen argued that computational requirements have kept moving up at GTC:
“The amount of computation we need at this point as a result of agentic AI and reasoning is easily 100x more than we thought we needed this time last year. Agentic AI at its foundation is reasoning. Remember, two years ago, when we started working with ChatGPT—a miracle as it was—many complicated questions and many simple questions, it simply can't get it right and understandably so. It took a one shot from whatever it had learned by studying pre-trained data and blurbs it out. Now, we have AIs that can reason step by step using a technology called Chain-of-Thought, with consistency checking and path planning.
As a result, the amount of tokens that's generated is easily 10x more and in order for us to keep the model responsive—so that we don't lose our patience waiting for it to think—we now have to compute 10x faster. So, 10x more tokens and 10x faster, the amount of computation we have to do is 100x easily. The combination of inference-time scaling and reinforcement learning has put an enormous computing challenge in front of the industry.”
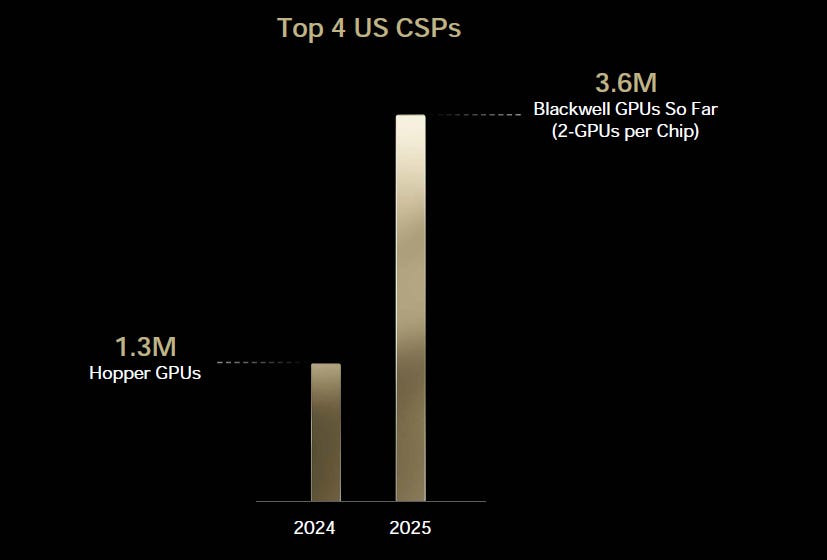
So this is the moment when Jensen showed the chart below which caused a bit of confusion, but it’s basically orders in the books from the top 4 cloud-service-providers (CSPs) compared to one year ago, indicating that the large clouds are massively ramping up GPU capacity:
So obviously demand growth is still very strong, and this was also confirmed by a data center architect at Microsoft Azure during a late March interview on Tegus:
“We're still very bullish on AI infrastructure. When it comes down to it, there were a couple projects that we ended up stopping. Our planned data center builds are very slightly down from what we thought. It wasn't that we outright just decided that there was not enough demand or anything like that. It was more so that the projects would not meet the deadlines and the schedule that had been communicated to us by the vendors.
With a couple of those, like one out in Ellendale, North Dakota, the vendor that we were working with just flat out said, "Hey, we're having issues. We don't think we can build at that pace," things like that. Given the outstanding timeline and just the investments we'd already made, we decided to cancel that project until the future at some point, whether or not they could get the schedule together, or whether or not we could find someone who could execute on it faster.
The infrastructure demand is still there. Over the last three months though, our CFO asked us to go through on these and make sure that as we build these data centers, that they'll definitely be profitable as soon as we light them up. There's just so many components to data centers. You get construction, you get the land, you've got transformers and all the equipment, HVAC and perimeter security, the labor challenges and stuff like that. With Amy wanting things to be profitable, some of the projects that we've had a look and said, "Unless we back this in, unless we move some of this equipment or unless we pull this forward, we're not going to be able to have it lit up and be profitable as soon as we turn it on."
But still bullish, still building at a very big pace. For like that Ellendale one, it was going to be build-to-suit and then we just decided to walk away from it. I know AWS the next day came in and said that they would be willing to go ahead and take that, because they're looking to build too. We're very good at building internally, but we're seeing if we can actually just outsource that to construction companies, have them build it and then we'll look at maybe a 10- or a 15-year lease on it.
But the current plan is to keep doing it until 2028. The overarching goal was to have 900 data centers by 2028. As to whether or not we build those or we lease them, we're shifting more towards leasing, but it's still to have around 900 by 2028. Originally, back in 2019, our goal was to do 100 data centers in a decade. But then back in 2020, when the pandemic hit, we realized there just was not going to be enough data centers out there for the compute demand and for AI. We went from a 100 in a decade to 100 per year. That number has been slowly going up. Originally we canceled some projects this year, but three of those projects actually just came back and we said we need to add them again. We basically uncanceled them.”
So while there have been concerns in the market around AI infrastructure demand in the coming years with DeepSeek and then press reports of Microsoft cancelling a number of data center projects, the overall outlook continues to be strong. The other main concern is around near term ROI and the need for an immediate killer app, but AI is already bringing in large cost savings at enterprises due to automation. Automated code generation is a big one here, allowing software engineers to be far more productive. We’re currently building a web app on the side and both Grok and DeepSeek are helping us out with that, and productivity levels go up massively. Bugs that could have taken us three or four hours to find, the AI can dive into the code and make a list of useful suggestions to solve it within five minutes.
So we’re very bullish on long term automation with AI and we suspect that massive apps will come. Obvious examples should be humanoid robotics and robotaxis later this decade, maybe even next year already. A final point here is that due to the huge potential of AI to automate large swaths of the economy, the final potential rewards are so huge—AGI—that as long as models keep making sufficient progress, the NPV calculation to keep investment levels high will be positive for the tech giants. So we don’t believe that ROI is the correct metric anyways, as long term capital investment decisions are actually made with NPV and IRR calculations, people at Sequoia should know better. Also, as the large tech giants really want to avoid being disrupted—which AI has the potential to do—the last thing they want is to lose this race. So it’s extremely likely that all the large names such as Google, Meta, Microsoft etc. will keep investment levels high as long as models keep making sufficient progress.
So Jensen’s chart caused some confusion at GTC, but all indications point to AI investment levels remaining robust in the coming years. This is Jensen giving some further background on the chart during the subsequent analyst meeting:
“Here's the question I was hoping to answer. Everybody is going like "with DeepSeek, the amount of compute that you need is like gone to zero and the CSPs, they're going to cut back on capex with rumors of somebody canceling." It was just so noisy, but I know exactly what's happening inside the system. The amount of computation we need has just exploded. Inside the system, everybody is dying for their compute, they're trying to rip it out of everybody's hands. So I didn't know exactly how to go about answering that question without just giving a forecast. And so I just took the top 4 CSPs and I compared it year-to-year, and I'm just simply trying to show that the top 4 CSPs are fully invested. They have lots of Blackwells coming. Here's the things that I didn't include and those obviously are quite large—the Internet services, for example X and Meta, I didn't include enterprise, car companies and AI factories, I didn't include international, a mountain of start-ups that all need AI capacity, I didn't include any of the robotics companies.”
As the large clouds are ramping up GPU capacity, this brings us to the battle for the AI cloud. Investors who are purely scrutinizing performance metrics of the various AI clouds to pick winners and stocks, we think that this is an ill-advised strategy. For premium subscribers, we will dive into this battle and with thoughts on where to position. Then, we will go much deeper into new developments in the AI data center, in AI and for Nvidia. Finally, we’ll review the financials and valuation for Nvidia, with thoughts on long term IRRs for investors in light of the recent stock market sell off.