

Nvidia’s Outlook
Once again, Nvidia beat its revenue guidance for the quarter with $2 billion, something they’ve been doing since the start of the current LLM investment cycle:
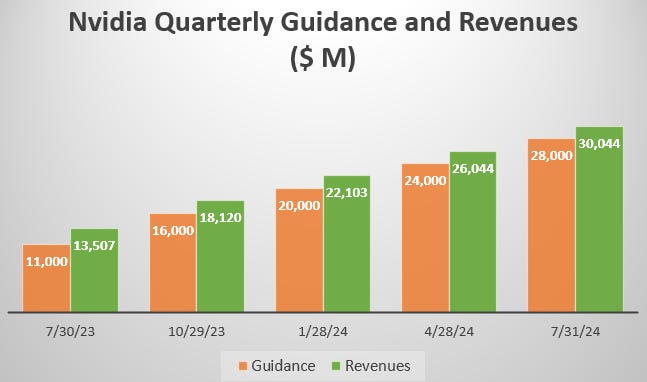
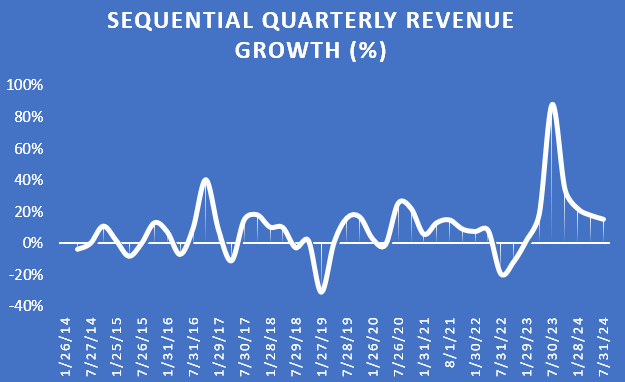
$30 billion of revenues in Q2 would mean that sequential growth rates are now starting to moderate to more normal levels seen during previous upcycles for Nvidia:
We discussed last month how the outlook for Nvidia remains solid, as we went through the value chain from TSMC to Tesla, Meta, Microsoft and Google, with all indicators confirming that Nvidia is on track to double its revenues this year. As just one example, with the help of some little math, you could back out that TSMC was basically saying that their AI revenues will grow 164% this year. While we saw this confirmed in the AI investments that Tesla and the hyperscalers are making.
The bull case for Nvidia investors is that currently still most demand has been coming from the AI training market whereas inference, the deployment of models to assist with tasks in the real world, will become the far larger semiconductor market. Over the last twelve months, Nvidia estimates that only 40% of demand has been coming from inference. This would mean we’ve only seen phase one of the AI GPU buildout really, with a further upwards trend to come in the next years as capacity constraints such as CoWoS and HBM get resolved by Nvidia’s supply chain.
However, I suspect that we will also see continuous upgrade cycles of training capacity to the latest state-of-the-art GPUs, as AI companies want an edge in the retraining their models. If you can be a few months faster to market with a leading LLM, this can make the difference between being a dominant player in the industry with a commanding market share such as OpenAI or being a more marginal follower. What will happen under this scenario is that the previous generation of GPU training capacity can be redirected to the inferencing market.
Although also here the argument can be made that if the latest GPUs have hundreds of milliseconds of advantage in responding to queries, that it would make sense to upgrade these to the latest release, as the user experience would be dramatically improved. Users will flock to the best and fastest models, as they did with Google Search in the search market. In that case older GPUs can still be redirected to serve the smaller type language models, which address more narrow tasks such as powering an ecommerce store.
So despite the tremendous growth Nvidia has been seeing, we still get the prospect of a buildout in the inference market, while compelling arguments can be made that at least part of the already installed capacity will have strong incentives to transition to the next generation Blackwell architecture.
Importantly for Nvidia, it looks like that inference buildout is happening. Microsoft’s head of Cloud AI recently discussed at JP Morgan how clients are deploying AI in real world use cases:
“We look at demand in 3 different aspects. So the first is customer demand. Both from those that are coming in in a pilot phase and then is that pilot translating into an at-scale deployment. So they're not just experimenting but they're actually taking it from experimentation into full-scale deployment.
A great example is Real Madrid. They have a very small set of their fans that live in Spain. They have over 500 million fans globally and they used AI to be able to create their fan engagement platform. They've increased their fan profile base by 400% and their top line revenue by 30%.
Volvo is another great example. They used a combination of cognitive services, generative AI to digitize all of their invoices. And so if you think about not only being able to invoice customers but all of the tracking that goes along with auto maintenance, they actually estimated that their new operational platform took out 850 manual hours per month.
The other dimension that we look at is our ecosystem. And so we look at the number of partners within our ecosystem that are getting AI specializations and where they are bringing in new customers. We have within our Azure AI services 53,000 active customers. 1/3 of those in the last year are new to Azure. So that is a great signal that we are not only bringing in existing customers but new customers as well.
And then the last dimension that we look at is customer commitment. Do we have customers making long-term commitments to the Microsoft platform? And our $100 million-plus contracts have increased 80% year-over-year.”
At the same time clients are transitioning to larger cluster sizes. This is Nvidia’s CFO discussing clusters being built by their customers:
“Large clusters like the ones built by Meta and Tesla are examples of the essential infrastructure for AI production, what we refer to as AI factories. These next-generation data centers host advanced full-stack accelerated computing platforms where the data comes in and intelligence comes out. In Q1, we worked with over 100 customers building AI factories ranging in size from hundreds to tens of thousands of GPUs, with some reaching 100,000 GPUs.”
Notice also that these clients are leveraging Nvidia’s full stack of GPU, networking and software solutions. Building a great GPU isn’t sufficient to start competing with this company.
As a result of these buildouts, Nvidia sees demand continuing to outstrip supply in the coming year. This is the company’s CFO again:
“While supply for H100 grew, we are still constrained on H200. At the same time, Blackwell is in full production. We are working to bring up our system and cloud partners for global availability later this year. Demand for H200 and Blackwell is well ahead of supply, and we expect demand may exceed supply well into next year.
Blackwell will be available in over 100 OEM and ODM systems at launch, more than double the number of Hoppers launched and representing every major computer maker in the world. This will support fast and broad adoption across the customer types, workloads, and data center environments in the first year shipments. Blackwell time-to-market customers include Amazon, Google, Meta, Microsoft, OpenAI, Oracle, Tesla, and xAi.”
xAI is Elon Musk’s latest startup with the aim of producing a truly open-source and truthful AI meant to compete with OpenAI’s ChatGPT and Google’s Gemini, both of which are closed-sourced and have been found in the past to be somewhat politically biased. Also Zuckerberg is going the open-source route with Meta’s Llama models, citing ecosystem and innovation advantages by leveraging the developer community from around the world.
This is Nvidia’s founder Jensen Huang on the Blackwell rollout and demand outlook:
“Our production shipments will start in Q2 and ramp in Q3, and customers should have data centers stood up in Q4. Blackwell comes in many configurations, it is a platform, not a GPU. And the platform includes support for air cooled, liquid cooled, x86, Grace, InfiniBand, Spectrum- X and NVLink. And so for some customers, they will ramp into their existing installed base of data centers that are already shipping Hoppers, they will easily transition from H100 to H200 to B100. Blackwell systems have been designed to be backwards compatible and of course, the software stack that runs on Hopper will run fantastically on Blackwell.
We see increasing demand of Hopper through this quarter and we expect demand to outstrip supply for some time as we now transition to H200, as we transition to Blackwell. Everybody is anxious to get their infrastructure online. The reason for that is because the next company who reaches the next major plateau gets to announce a groundbreaking AI and the second gets to announce something that's 0.3% better. And so the question is, do you want to be repeatedly the company delivering groundbreaking AI or the company delivering 0.3% better? And that's the reason why this race, as in all technology races, the race is so important. The difference between time-to-train that is three months earlier is everything. So it's the reason why we're standing up Hopper systems like mad right now, because the next plateau is just around the corner.
And then after Blackwell, we have other Blackwells coming. We're in a 1-year rhythm as we've explained to the world. How is it that we're moving so fast? Because we have all the stacks, we literally build the entire data center and we can monitor everything, measure everything and optimize across everything. We know where all the bottlenecks are. If you invest today on our software stack, it's just going to get faster and faster. If you have a $5 billion infrastructure and you improved the performance by a factor of 2, which we routinely do, the value to you is $5 billion. The highest performance is also the lowest cost. And if you invest in our architecture today, it will go to more and more clouds and more and more data centers and everything just runs.”
A number of competitors have been making the argument that due the lower pricing of their GPUs, that the TCO of their GPUs is better for AI workloads. However, the points above made by Jensen illustrate really well why the leading AI companies mostly go for Nvidia’s GPUs, with the exception of Google who is training on their own TPUs.
Firstly, you get the best performance with Nvidia’s GPUs and thus the lowest latency and fastest time to market. Secondly, while your capex is higher, you benefit from Nvidia’s huge R&D machine which is consistently improving the entire stack. During the last quarter for example, thanks to algorithm innovations, the company was able to accelerate LLM inference by up to three times, giving 3x cost reductions and lower latencies to clients. Finally, as Nvidia’s ecosystem is deployed in every major cloud, it allows customers to roll out their AI workloads on any cloud, giving tremendous elasticity to scale instantaneously when needed.
For premium subscribers, we’ll review:
Nvidia’s ethernet pivot
The China trump card
A detailed look at the financials and valuation for the company